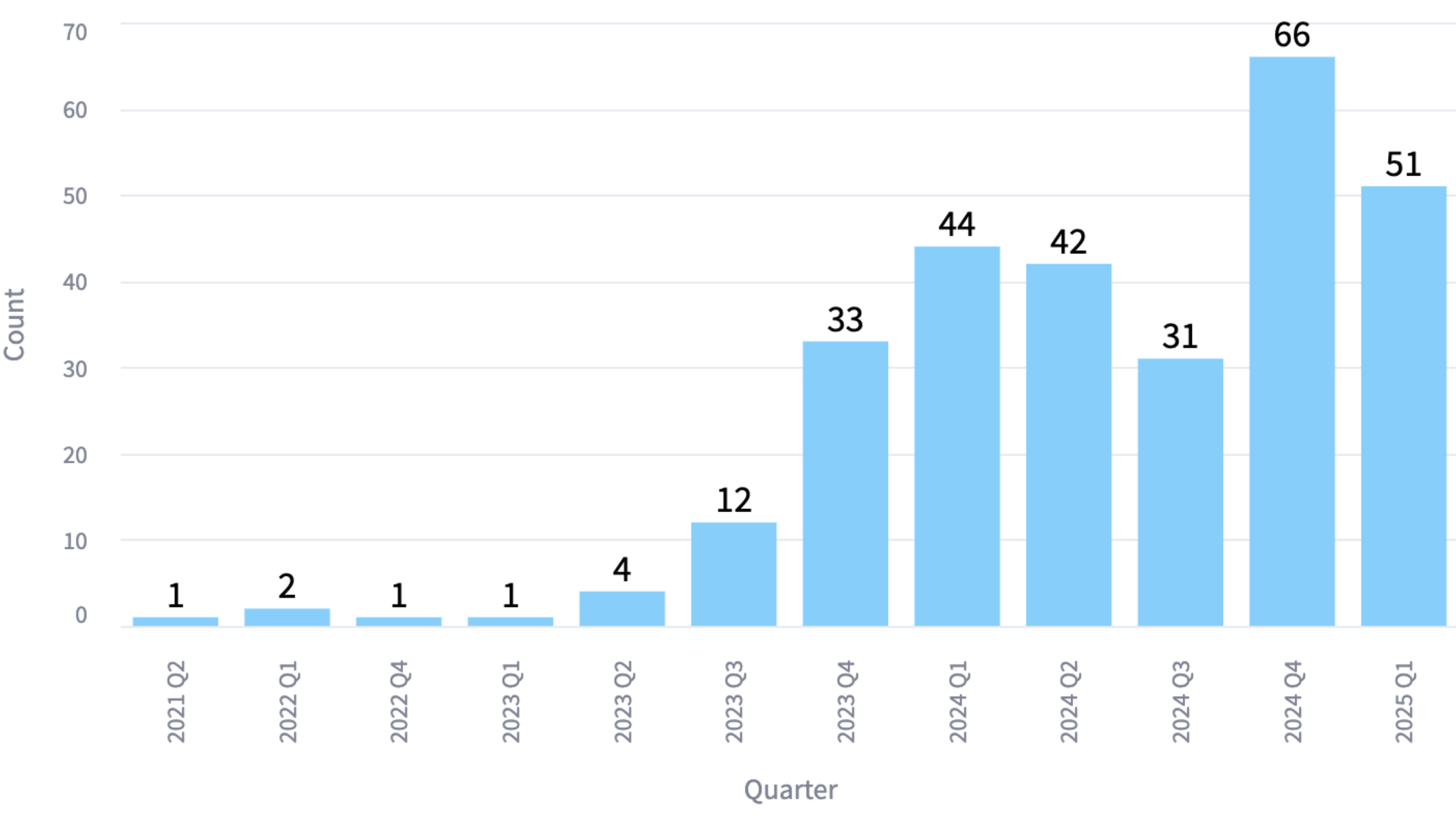
Papers on visual reasoning per quarter over the last three years, with state computed using referenced papers. (Data current to mid-March 2025.)
Reasoning Foundation
Reasoning is fundamental to human intelligence, enabling structured problem-solving across diverse tasks.
Recent advances in LLMs have greatly enhanced reasoning abilities in arithmetic, commonsense, and symbolic domains through techniques like Chain-of-Thought prompting.
Multimodal Challenge
Extending reasoning to multimodal contexts remains challenging, as models must integrate visual and textual inputs while resolving ambiguities and conflicting information across modalities. This requires sophisticated interpretative strategies.
Background & Problem Formulation
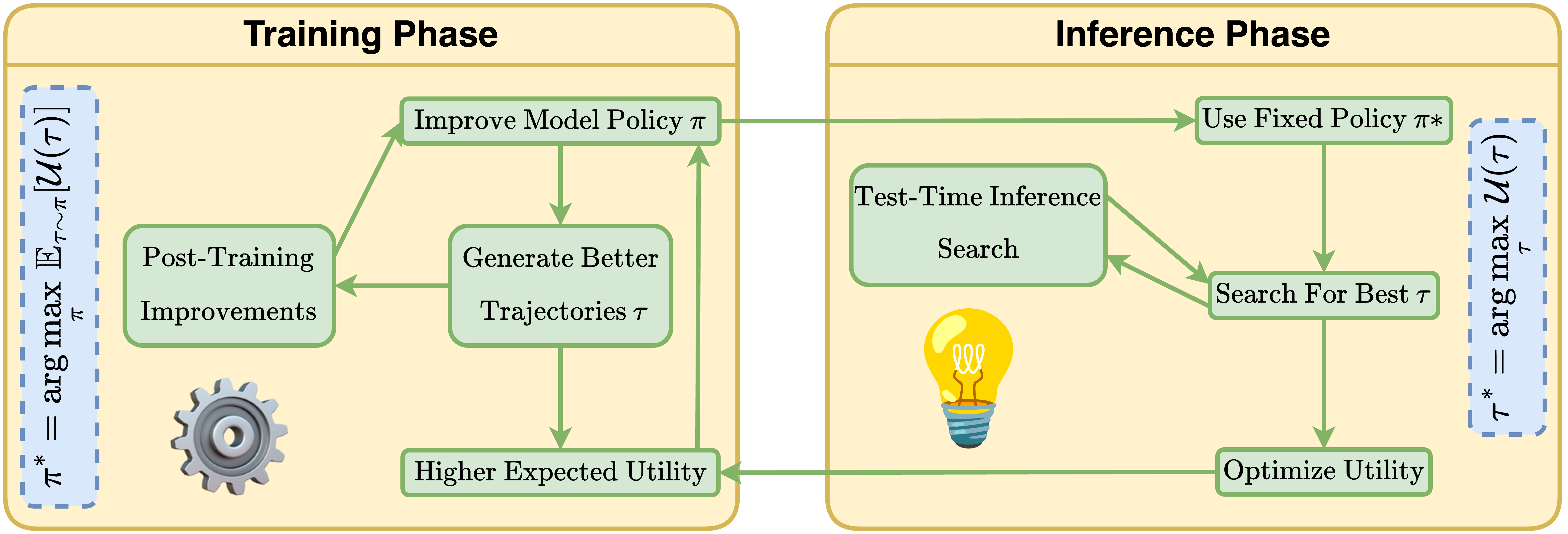
Framework illustrating training and inference for reasoning optimization. A virtuous cycle emerges as better policies generate improved trajectories, which in turn enhance the model through stronger supervision.
In complex question-answering tasks, directly predicting an answer can be highly uncertain due to the vast range of possible responses.
A more effective approach involves breaking down the reasoning process into a sequence of intermediate steps. This structured method not only improves interpretability but also helps reduce uncertainty at each inference step.
Formally, let $Q$ denote a given question. Conventional language models typically aim to model the conditional probability $P(A \mid Q)$ of the answer $A$ given the question. However, as the complexity of $Q$ increases, the prediction becomes more uncertain. A natural approach to mitigate this uncertainty is to decompose the reasoning process into a sequence of intermediate steps:
$P(\text{Step}_1 \mid Q) \cdot P(\text{Step}_2 \mid \text{Step}_1, Q) \cdot \ldots \cdot P(\text{Step}_t \mid \text{Step}_{1:t-1}, Q) \cdot P(A \mid \text{Step}_{1:t}, Q)$
This step decomposition is useful because conditioning on prior steps reduces uncertainty. The entire reasoning process can be viewed as a trajectory $\tau = (\text{Step}_1, \ldots, \text{Step}_t)$, which represents a complete reasoning path.
Search framework where language models explore and refine reasoning paths. Trajectories are scored using reward models, based on expected utility or final output quality, and guided by feedback, world models, and evaluators to select the most promising steps.
Test-Time Computation
At test time, the goal is to find the reasoning trajectory τ that maximizes a utility function. The utility can be defined in various ways, including cumulative rewards (MDP-style), goal likelihood, preference comparisons, and ranking-based scores. Since directly modeling utility is often difficult, we use reward models to approximate it through absolute rewards, pairwise preference models, and ranking-based approaches.
Search Strategies
Monte Carlo Tree Search (MCTS) has emerged as a powerful tool for managing uncertainty and sequential decision-making in multimodal reasoning. Recent advances include CoMCTS, which unifies multiple MLLMs within a collaborative tree search framework, addressing model bias and improving both accuracy and efficiency. Vision-specific strategies have advanced with methods like VisVM, which estimates long-term candidate value to reduce hallucinations, outperforming immediate-alignment approaches.
Structured search methods have gained significant traction. LLaVA-o1 uses stage-level beam search for complex reasoning tasks, breaking them into manageable components. MVP aggregates certainty across multi-perspective captions to resist adversarial inputs, while DC2 applies MCTS-based cropping to focus on salient image regions for high-resolution reasoning.
Multimodal and temporal search frameworks like VideoVista, WorldRetriever, and DynRefer surpass static baselines using adaptive sampling, fusion, and stochastic inference. These approaches highlight the shift toward adaptive visual reasoning through context refinement, image decomposition, and dynamic tool use.
Adaptive Inference
Adaptive inference reshapes vision-language reasoning by enabling dynamic, context-sensitive processing that improves both accuracy and efficiency. Central to this approach is the iterative evaluation and refinement of outputs through internal feedback and external verification.
Iterative refinement methods include LOOKBACK, which enhances correction accuracy through iterative visual re-examination within each reasoning step, and IXC-2.5, which balances performance and response length via Best-of-N sampling guided by reward models. PARM++ uses reflection-based refinement to align generated images with prompts more effectively.
Hallucination mitigation is addressed through several innovative approaches. MEMVR triggers visual retracing based on uncertainty, optimizing cost-accuracy tradeoffs, while MVP aggregates certainty across diverse views. SID applies token-level contrastive decoding to filter irrelevant content, maintaining reasoning efficiency while reducing errors.
Reward Models and Feedback
Outcome-based Reward Models (ORMs) evaluate reasoning traces based on final outcomes, typically correctness or answer quality. Recent advances like PARM++ have expanded ORMs by employing iterative reflection mechanisms at inference-time, where refinement based on outcome verification markedly improves model outputs without retraining.
Process-based Reward Models (PRMs) differ by rewarding each intermediate reasoning step, promoting coherent reasoning processes. Methods like FuRL align VLM outputs more robustly with task objectives by assessing step-wise advantages, significantly outperforming approaches that only consider final outcomes.
Self-critique approaches like LOOKBACK systematically re-examine intermediate visual inferences, correcting persistent errors and significantly enhancing multimodal reasoning accuracy. Visual Programming and Debugging (VPD) provides robust internal feedback mechanisms, improving reasoning coherence without external supervision.
Efficiency and Scalability
Recent research emphasizes improving efficiency and scalability in vision reasoning through innovative architectures and computational strategies. MaGNeTS introduces nested neural networks that dynamically adjust complexity across iterations, achieving substantial reductions in computational costs.
Multi-modal efficiency improvements include MVOT, which integrates visualizations with thought processes using token discrepancy loss, and SID, which introduces contextualized token-to-sentence contrastive decoding to maintain reasoning efficiency while mitigating hallucinations.
Video reasoning efficiency is addressed by VIDEOTREE, which proposes adaptive hierarchical clustering and tree-based video navigation, significantly reducing frame requirements compared to traditional summarization methods while enabling efficient reasoning on lengthy video inputs.
Key Insights
Search Strategies: Current algorithms primarily operate on textual tokens, but innovative approaches are emerging for raw visual tokens through Creative Visual Search, expanding capabilities directly within visual spaces.
Reward and Feedback: Reward systems benefit significantly from deeper visual insights. Leveraging visual prompts encourages models to engage in self-reflection grounded in visual information, improving semantic alignment and decision-making effectiveness.
Iterative Refinement: While determining alignment between textual and visual information remains challenging, model self-reflection offers valuable insights for enhancing reliability and mitigating hallucinated interpretations.
Citation
If you found this work is useful in your own research, please considering citing the following.
@article{bi2024reasoning,
title={Why Reasoning Matters? A Survey of Advancements in Multimodal Reasoning},
author={Bi, Jing and Liang, Susan and Zhou, Xiaofei and Liu, Pinxin and Guo, Junjia and Tang, Yunlong and Song, Luchuan and Huang, Chao and Vosoughi, Ali and Sun, Guangyu and He, Jinxi and Wu, Jiarui and Yang, Shu and Zhang, Daoan and Chen, Chen and Wen, Lianggong Bruce and Liu, Zhang and Luo, Jiebo and Xu, Chenliang},
journal={arXiv preprint arXiv:2504.03151},
year={2024}
}
